AI Model Comparison Platform
Stop vibing with
the wrong AI
Find which AI model gives the best response to your prompt from Claude Code, Codex or with our Desktop App.
Sponsored by ![]() Knowatoa
Knowatoa
Find which AI model gives the best response to your prompt from Claude Code, Codex or with our Desktop App.
Sponsored by ![]() Knowatoa
Knowatoa
Every comparison reveals something new about your AI stack.
"I found that GPT-4o-mini outperformed GPT-4o on our classification task—and it's 15x cheaper."
Ran 200 product descriptions through both models. Mini scored 94% vs 4o's 91% on our labeled test set.

"Gemini Flash with JSON mode had zero parsing errors. Without it, 12% failed."
Structured output testing across 500 API calls.

"Temperature 0.3 was the sweet spot—0 was too rigid, 0.7 too creative for our use case."
Tested 5 temperature settings across our eval dataset.

"Adding 'think step by step' improved Claude's accuracy by 23% on math problems."
Same prompt, with and without chain-of-thought. Night and day difference.

"Our V3 prompt worked great on GPT-4o but terribly on Gemini. Now we use different prompts per model."
Cross-model testing revealed prompts aren't one-size-fits-all.

"Llama 3.1 70B via OpenRouter matched Claude Sonnet quality at 1/3 the cost."
Ran our full test suite. Open source is catching up fast.

Run your prompts across models, configs, and datasets. The insights are waiting.
Connect OpenAI, Anthropic, Google, or OpenRouter. Keys are stored locally—never on our servers.
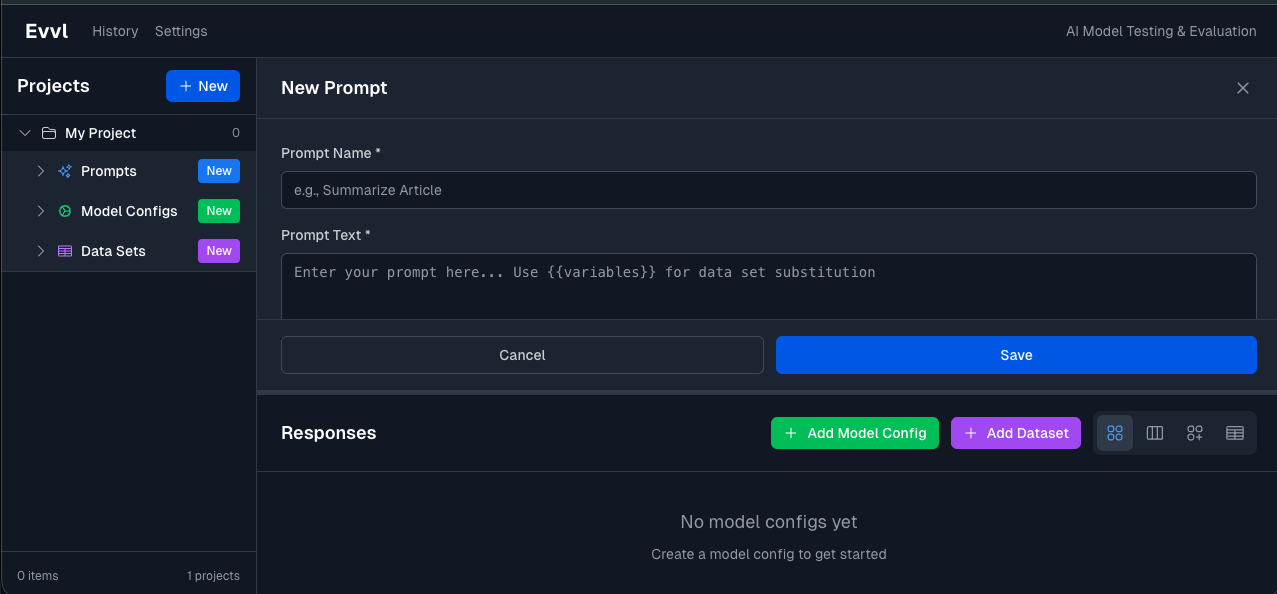
Enter the prompt you want to test, add variables and track results across versions.
Choose which models to compare, either the same model with different configuration parameters or two different models from different providers.
Upload test cases or create them inline to run your prompts against real-world inputs.
View all responses side by side. Add notes, export results, and build intuition about which models work best.
Export comparisons to JSON or CSV. Share findings with your team or document your evaluation process.
We built Evvl with privacy as a core principle.
API keys, prompts, and outputs are stored only in your browser. Clear your data and it's gone.
API keys are automatically redacted from all server logs. Prompts are never logged.
Web app uses cookie-free Plausible analytics. Desktop app has zero tracking.
For maximum privacy—API calls go directly to providers with no intermediary.
Yes, Evvl is completely free. You bring your own API keys and pay those providers directly for usage.
Locally in your browser (web app) or on your machine (desktop app). Never on our servers. Learn more.
Same features. Desktop makes all API calls directly to providers. Web must proxy some calls (OpenAI, Anthropic) due to CORS. See details.
OpenAI, Anthropic, Google, and OpenRouter (which gives access to 100+ additional models including Llama and Mistral).
Yes. Export comparisons and notes to JSON or CSV for analysis, sharing, or archiving.
Evvl was built by the team at Knowatoa to help with our own software development. We needed a better way to compare AI models and decided to share it with everyone.











